Uno de los retos que sueles encontrarte en el mundo de las bases de datos a nivel técnico es que sean capaces de almacenar muchos millones de documentos (filas) y a la vez sean capaces de encontrar el resultado (una aguja en un pajar) en muy pocos milisegundos.
Si tienes un proyecto pequeño y una base de datos que se maneja en gigas de datos, las soluciones son sencillas de implementar. Con algunos ajustes en la capa de aplicación (si los puedes meter) y alguna que otra capa de cache, tu base de datos rejuvenece unos cuantos años.
Si la base de datos ya es de un tamaño considerable y hablamos de teras de información, es probable que ya tengas oídos los términos como cluster, sincronización, maestro y esclavos, además de las expresiones «necesitamos más disco», «el backup va muy lento» o «¿puedo tener una copia en local?» que pueden hacerte perder la cabeza por momentos.
Dependiendo del proyecto, puedes apoyarte en la arquitectura, gastando un buen montón de euros adicionales para mejorar la respuesta de tus bases de datos.
Pero, si no dispones de presupuesto para montar un Oracle Exadata y Oracle Coherence (por poner un ejemplo famoso) y tu proyecto puede aprovecharse de una base de datos NoSQL, es muy interesante que le pegues un vistazo a MongoDB.
Con MongoDB puedes crear de forma muy sencilla una plataforma que puede crecer tanto en redundancia (ReplicaSet) como en almacenamiento (Sharding), manteniendo siempre un muy buen nivel de capacidad de respuesta.
La configuración es bastante sencilla y amigable. Entrar a nivel de detalle de configuración te llevará muy poco tiempo y podrás hilar muy fino (si tu proyecto lo requiere) para configurar y adaptar las máquinas de bases de datos a tus necesidades. Con pocos euros, obtendrás unos resultados que pocos te podrán discutir.
Para medir esos resultados no hace falta que montes un Munin o un Ganglia que muestre las gráficas típicas que te dan mucha información interesante de un simple vistazo. Puedes utilizar el servicio de MongoDB Management Service (MMS) para ello. Instalando un simple agente en tus nodos, en pocos minutos tendrás toda una lista de gráficas muy completas que mostrarán información ordenada de que está ocurriendo con tu base de datos.
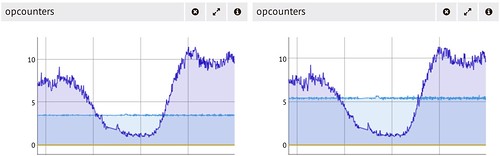
En la captura de arriba se pueden ver las gráficas de un par de nodos de un ReplicaSet. En el MMS puedes organizar uno o más tableros donde colocar las gráficas que te interesan para cada cosa concreta, haciéndote la vida más fácil si necesitas ver el estado de tu granja de servidores de base de datos de un vistazo.
Yo he implementado MongoDB + MMS ya en bastantes nodos de distintos proyectos y entornos productivos. La ventaja de tener en muy poco tiempo toda una solución compleja de base de datos lo convierte en un producto muy, muy, muy interesante para proyectos donde se trabaje con grandes cantidades de datos.
¿Todavía no lo has probado? ;)